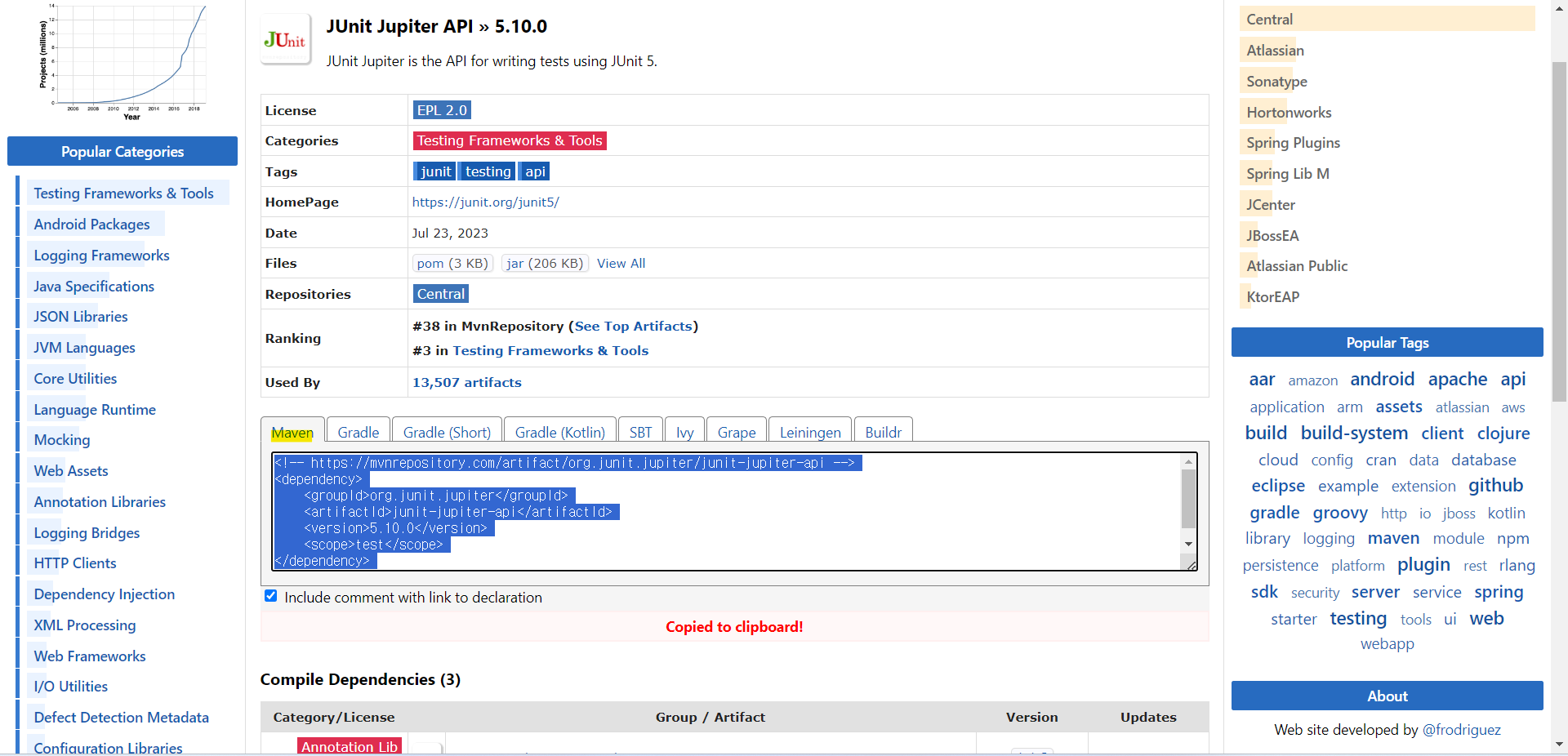
@TestInstance : 각각의 단위 테스트 메서드를 수행할 때, 안전한 결과를 얻어내기 위해 테스트 클래스로부터 테스트 객체를 어떠한 기준으로 생성할 지 결정하는 어노테이션입니다. 해당 어노테이션의 속성은 'PER_CLASS'와 'PER_METHOD'가 이며 defualt는 'PER_CLASS'입니다.
- PER_METHOD(기본값) : 단위 테스트 메서드마다 테스트 객체 생성 후 테스트 메서드를 수행합니다. - PER_CLASS : 하나의 테스트 객체만 생성 후, 모든 단위 테스트 메서드를 수행합니다.
다만 PER_METHOD는 메모리에 부담을 주기 때문에 개발환경을 고려하여 설정해야 합니다.
@TestMethodOrder : 모든 단위 테스트 메서드의 실행순서의 기준과 방법을 설정합니다. 다양한 속성이 있지만, 주로 OrderAnnotation(@Order, 서수)을 사용합니다.
테스트 클래스 블록 어노테이션
전처리 어노테이션
@BeforeAll : 단위 테스트 메서드 수행 시, 오직 한 번만 수행되는 전처리입니다.
@BeforeEach : 단위 테스트 메서드 수행 시 매번 수행되는 전처리입니다.(JUnit4의 @Before와 동일)
@AfterAll: 단위 테스트 메서드 수행 시, 오직 한 번만 수행되는 후처리입니다.
@AfterEach: 단위 테스트 메서드 수행 시 매번 수행되는 후처리입니다.(JUnit4의 @Before와 동일)
후처리 어노테이션
@Disabled : 단위테스트 메서드를 제외시킵니다.
@Tag: 단위 테스트의 성격(fast,normal, slow)을 표시합니다.
@Test: 메서드가 단위 테스트용임을 표시합니다.
@Order: 단위 테스트 메서드의 수행 순서를 결정합니다.
@DisplayName: 테스트 도구에 표시되는 단위 테스트의 이름입니다. JUnit View에서 해당 어노테이션으로 설정한 이름으로 보여줍니다.
@Timeout: JUnit4에서는 @Test의 속성이었습니다. 하지만, JUnit5에서는 다양한 시간 단위로 테스트의 임계 소요 시간을 정의할 수 있도록 분리하여 사용합니다. 속성으로 value와 unit이 있습니다.
예를 들어, 0.5초 안에 테스트를 종료해야 한다면 다음과 같이 코드를 작성할 수 있습니다. @Timeout(value = 500L, unit = TimeUnit.MILLISECONDS)
다음은 간단한 JUnit5 테스트 코드 작성법입니다.
@Log4j2
@NoArgsConstructor
// 1. 타입 선언부에 적용해야할 JUnit Jupyter Annotations입니다.
@TestInstance(Lifecycle.PER_CLASS)
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
public class JUnitJupiterTemplateTests {
@BeforeAll
void beforeAll() { // 1회성 전처리
log.trace("beforeAll() invoked.");
// TODO here.
} // beforeAll
@BeforeEach
void beforeEach() { // 매번 수행되는 전처리
log.trace("beforeEach() invoked.");
// TODO here.
} // beforeEach
@AfterAll
void afterAll() { // 1회성 후처리
log.trace("afterAll() invoked.");
// TODO here.
} // afterAll
@AfterEach
void afterEach() { // 매번 수행되는 후처리
log.trace("afterEach() invoked.");
// TODO here.
} // afterEach
// ------------------------------------------------
@Disabled
@Tag("fast")
@Test
@Order(1)
@DisplayName("contextLoads")
@Timeout(value = 500L, unit = TimeUnit.MILLISECONDS)
void contextLoads() { // 단위 테스트 메서드
log.trace("contextLoads() invoked.");
} // contextLoads
} // end class
예를 들어, LEFT OUTER JOIN이라면 왼쪽 테이블의 모든 행을 기준으로 오른쪽 테이블을 JOIN합니다.
다음은 OUTER JOIN에 대한 쿼리입니다.
-- Oracle LEFT OUTER JOIN --
SELECT
e.last_name AS 사원명,
e.employee_id AS 사원번호,
m.last_name AS 관리자명,
m.employee_id AS 관리자사번
FROM
employees e,
employees m
WHERE
e.manager_id = m.employee_id (+);
-- Ansi LEFT OUTER JOIN --
SELECT
e.last_name AS 사원명,
e.employee_id AS 사원번호,
m.last_name AS 관리자명,
m.employee_id AS 관리자사번
FROM
employees e LEFT OUTER JOIN employees m -- OUTER 키워드 생략 가능 --
ON e.manager_id = m.employee_id;
RIGHT OUTER JOIN도 동일한 개념으로 동작합니다.
그런데 Ansi JOIN에서만 있는 FULL OUTER JOIN이 있습니다.FULL OUTER JOIN은 두 테이블의 모든 행을 결합하되, NULL값을 모두 포함하여 결합합니다.
-- Ansi FULL OUTER JOIN --
SELECT
e.last_name AS 사원명,
e.employee_id AS 사원번호,
m.last_name AS 관리자명,
m.employee_id AS 관리자사번
FROM
employees e FULL OUTER JOIN employees m -- OUTER 키워드 생략 가능 --
ON e.manager_id = m.employee_id;
만약 출력하고 싶지 않은 필드가 있다면 해당 필드에 transient 키워드를 붙이면 됩니다.
다음은 직렬화에 대한 코드입니다.
ClassA
@Data
public class ClassA implements Serializable {
private int field1; // 일반 필드 생성
ClassB field2 = new ClassB(); // ClassB 객체 생성
static int field3; // 정적 필드 생성
transient int field4; // 한정자(transient) 필드 생성, 직렬화 제외
} // end class
클래스B와 클래스C는 간단한 필드만 선언되어 있습니다.
ClassB
@ToString
@NoArgsConstructor
public class ClassB implements Serializable {
int field1;
} // end class
ClassC
@ToString
@NoArgsConstructor
public class ClassC implements Serializable {
int field1;
} // end class
메인 스트림에서 지정한 경로에 필드의 정보를 출력합니다.
SeriaizableWriter
public class SerializableWriter {
public static void main(String[] args) throws Exception{
// @Cleanup 어노테이션으로 자동 자원 해제
@Cleanup FileOutputStream fos = new FileOutputStream("C:/Temp/Object.dat");
@Cleanup ObjectOutputStream oos = new ObjectOutputStream(fos);
ClassA classA = new ClassA(); // 기본 생성자로 객체 생성
classA.setField1(1); // 고유속성 초기화
classA.field2.field1 = 2; // 부품필드 초기화
ClassA.field3 = 3; // 정적필드 초기화
classA.field4 = 4; // transient 한정자가 붙은 필드
// ClassA타입의 객체를 파일에 출력(ObjectOutputStream)
oos.writeObject(classA);
oos.flush();
} // main
} // end class
위 실행 클래스가 정상적으로 동작되었다면, Temp 폴더에 Object.dat 파일이 생성됩니다.
이제 Object.dat 파일을 읽는 실행 클래스를 만들겠습니다.
@Log4j2
public class SerializableReader {
public static void main(String[] args) throws Exception{
@Cleanup FileInputStream fis = new FileInputStream("C:/Temp/Object.dat");
@Cleanup ObjectInputStream ois = new ObjectInputStream(fis);
ClassA objA = (ClassA) ois.readObject();
log.info("1.field1: {} ", objA.getField1());
log.info("2.field2.field1: {} ", objA.field2.field1);
log.info("3.field2: {} ", ClassA.field3);
log.info("4.field3: {} ", objA.field4);
} // main
} // end class
입력받은 각 필드의 키워드는 다음과 같습니다.
field1 = classA_private int field1 = 1
field2 = classA_classB_int field1 = 2
field3 = classA_static int field3 = 3
field4 = classA_transient int field4 = 4
다음은 출력 결과입니다.
조회 결과
보시는 것처럼,
Serializable를 Implements하는 클래스에 있는 필드들의 출력 파일을 입력받았는데
field3 과 field4는 결과값이 없는 것을 알 수 있습니다.
그렇다면, 파일을 출력하는 과정에서 field3와 field4가 출력되지 않았다고 예상됩니다.
가장 먼저 field 4는 transient 키워드가 붙어있기 때문에 애초에 출력이 되지 않습니다.
field3를 출력하지 못하는 이유는 메모리 영역에서 알 수 있습니다.
객체의 정보(필드)는 힙 메모리 영역에 저장되는 반면 정적 필드는 static 영역에 저장됩니다.
즉, 객체 입출력 스트림은 객체의 정보(필드)를 출력하고 읽는 스트림인데,
일반 필드가 저장되어 있는 힙 영역과 정적 필드가 저장되는 static 영역은 완전히 별개의 영역이기 때문에 입력받지 못하는 것입니다.
마지막으로 간단한 예제를 통해 조금 더 심도있게 살펴보겠습니다.
Parent
@ToString
@NoArgsConstructor
public class Parent {
// Getter, Setter를 사용하지 않고 도트로 접근하기 위해 public
public String field1;
} // end class
Child
@Log4j2
@ToString
@NoArgsConstructor
public class Child
extends Parent
implements Serializable {
private static final long serialVersionUID = 1L;
public String field2;
// 자바언어표준스펙에서 정의된 메서드를 사용함, 직렬화
private void writeObject(ObjectOutputStream out)
throws IOException {
log.trace("writeObject({}) invoked.", out);
// 이 메서드 안에서, 확장받은 부모 객체의 필드가 직렬화 가능하도록
// 상속받은 부모객체의 필드를 직접적으로 출력
out.writeUTF(field1);
out.defaultWriteObject();
} // writeObject
// 역직렬화
private void readObject(ObjectInputStream in)
throws IOException, ClassNotFoundException {
log.trace("readObject({}) invoked.", in);
// 이 메서드 안에서, 확장받은 부모 객체의 필드가 역직렬화 가능하도록
// 상속받은 부모객체의 필드를 직접적으로 입력
field1 = in.readUTF();
in.defaultReadObject();
} // readObject
} // end class
위 코드에서 serialVersionUID 필드는 만약 클래스가 변경(예를 들어, 필드가 추가되거나 삭제)되면 직렬화된 객체의 형식과 해당 클래스의 형식을 맞추기 위해 사용됩니다.
serialVersionUID는 직렬화/역직렬화 과정에서 클래스 버전을 확인하고 만약 serialVersionUID의 값이 동일하다면 필드의 정보 상관없이 역직렬화할 수 있습니다.
Child 클래스에서 선언된 메서드들은 자바 언어 표준 스펙에서 정의된 메서드를 사용하였습니다.해당 메서드들은 직렬화/역직렬화를 할 때, JVM이 자동으로 콜백(callback)을 합니다. 즉, 이 메서드를 사용함으로써 Serializable하지 못한(직렬화/역직렬화가 불가능한) Parent 클래스의 객체 정보도 직렬화/역직렬화를 가능하게 만듭니다.
다음은 실행 클래스 입니다.
@Log4j2
public class NonSerializableParentExample {
public static void main(String[] args) throws Exception{
@Cleanup FileOutputStream fos = new FileOutputStream("C:/Temp/Object.dat");
@Cleanup ObjectOutputStream oos = new ObjectOutputStream(fos);
// 필드 초기화
Child child = new Child();
child.field1 = "홍길동";
child.field2 = "홍삼원";
// 부모가 serializable하지 않아도 직렬화 가능함
oos.writeObject(child);
oos.flush();
log.info("write done.\n");
// ===================================================
@Cleanup FileInputStream fis = new FileInputStream("C:/Temp/Object.dat");
@Cleanup ObjectInputStream ois = new ObjectInputStream(fis);
Child childObj = (Child) ois.readObject();
// Serializable하지 않은 Parent Class의 필드 정보는 역직렬화 불가능함
log.info("1.field1: {}", childObj.field1);
log.info("2.field2: {}", childObj.field2);
} // main
} // end class
입출력을 하나의 클래스에서 구현하였습니다.
다음은 코드 결과입니다.
Child 클래스에서 메서드를 선언했을 때, 결과
보시는 것처럼, JVM은 Parent 클래스가 직렬화/역직렬화가 불가능하다는 것을 알고 Child 클래스의 메서드를 자동으로 콜백하였습니다.
만약 Child 클래스에 해당 메서드가 없다면 어떻게 될까요?
Child 클래스에서 메서드 주석처리
콘솔 결과에서도 알 수 있듯이, Parent 클래스에 속한 field1 필드가 null값으로 입력된 것을 확인할 수 있습니다.
즉, JVM이 직렬화/역직렬화가 불가능한 클래스를 발견하고 콜백할 메서드를 찾지 못하면 직렬화/역직렬화를 못한 상태로 입/출력이 이루어지게 됩니다.